Copy PySpark Schemas to Clipboard

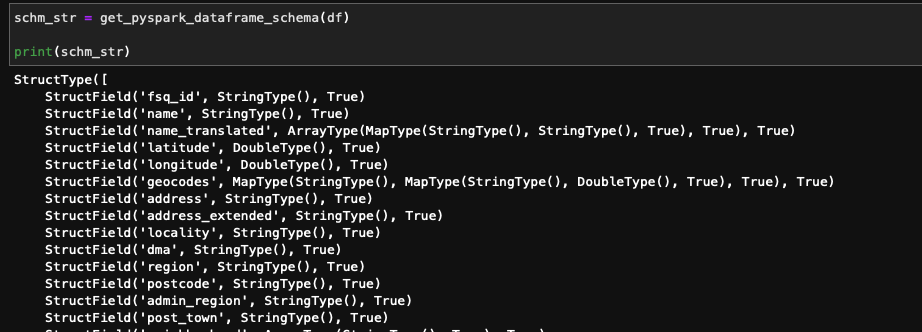
Frequently, I have a need to both explicitly define input data schemas for processing using PySpark and simultaneously include the schema in Sphinx documentation. Usually I can get the schema for loading without too much difficulty by outputting df.schema in a Jupyter Notebook, and copy-paste into my loading method. Then, for the documentation, I can get the schema by doing a copy-paste of the output from df.printSchema to my documentation. Still, I wanted something a little simpler, something a little more concise and efficient.
Pandas has the ability to send a Pandas data frame directly to the clipboard, so I started by investigating how Pandas does this. I discovered Pandas does a lot of work to make this happen. Fortunately, it can directly be accessed to pass any string in through the pandas.io.clipboards.clipboard_set method.
Since many of the environments I work in, notably some Spark clusters, do not always have Pandas by default, I wrapped this up in a succinct function to at least provide an understandable error if Pandas is not available.
This addresses getting any string to the clipboard, but we still need a way to get the two representations of the PySpark DataFrame schema, the one for explicitly defining the schema when reading data, and the one for documentation. The two functions below take care of this.
These can be used together with the clipboard function for quickly getting a data frame schema to the clipboard in both formats. Since this is something I find myself frequently doing in different projects, I tossed these functions into the Gists referenced above so I can get to them, but also just in case you may also be able to benefit from having these quickly available!