Loading a Previously Saved SpatialDataFrame from CSV

Increasingly I find myself working with SpatialDataFrames for analysis in Jupyter Notebooks in Python. Much of the time the easiest way to save results for future work is saving to a CSV file. This CSV file can then be loaded back into another notebook as an active SpatialDataFrame for further analysis provided you take into account how the geometry column, the SHAPE field is saved. The geometry column is saved as a long string, but it needs to be recast back into a list, or Pandas Series, of Geometry objects for the SpatialDataFrame.
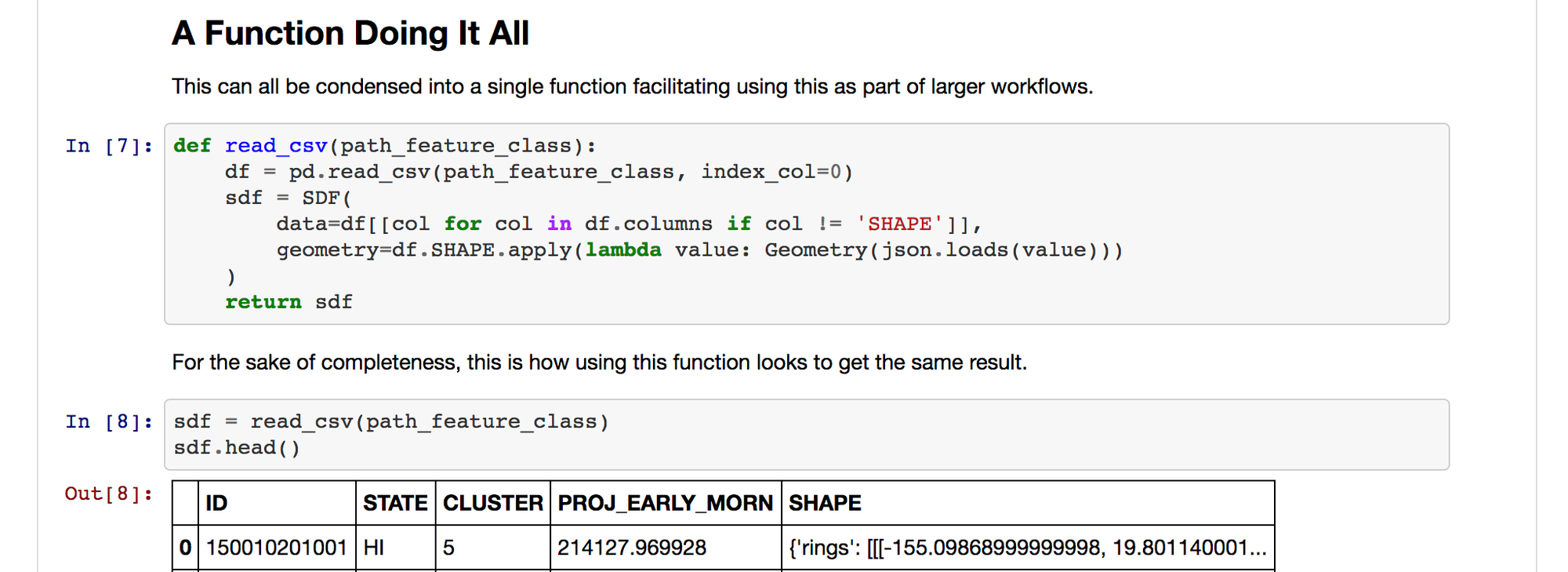
For the impatient, here is the concise function accomplishing this task.
def read_csv(path_feature_class):
df = pd.read_csv(path_feature_class, index_col=0)
sdf = SDF(
data=df[[col for col in df.columns if col != 'SHAPE']],
geometry=df.SHAPE.apply(lambda value: Geometry(json.loads(value)))
)
return sdf
If you want to see what is going on in a little more interactive walkthrough of all the steps to get here, I also have created a Gist of the Jupyter Notebook explaining the process in a slightly more stepwise manner.