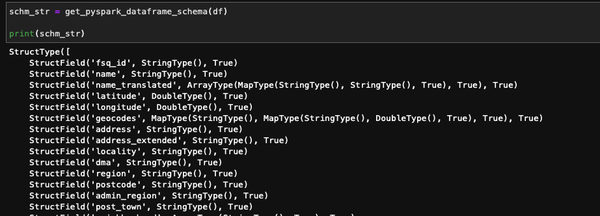
Frequently, I have a need to both explicitly define input data schemas for processing using PySpark and simultaneously include the schema in Sphinx documentation. Usually I can get the schema for loading without too much difficulty by outputting df.schema in a Jupyter Notebook, and copy-paste into my loading